
 ×
×
PyTorch × Transformers Journey
Pythonicity, Autodiff & Modularity in Modern AI
Pablo Montalvo‑Leroux · ML Engineer @ Hugging Face
2016‑2018: Backprop & Birth Pangs
The journey began with uncertainty: back in 2016, machine learning was far from standardized. Tools like Theano and CNTK were fading, and many of us—myself included—were jumping framework to framework. It was a time of raw experimentation.
- Frameworks were in flux; few stuck around.
- MLPs evolved to RNNs and LSTMs.
- 2017, Attention, then 2018: BERT arrives, blowing the roof off what's possible.
But reproducing results remained frustratingly difficult.
Transformers × PyTorch: Reproducibility
That all changed with pytorch-pretrained-bert, the predecessor to Transformers. Suddenly, the magic of BERT was available in an interface that made sense.
🧩 Simpler Interface
No static graphs, just Python functions and PyTorch modules.
✨ Hackability
Readable, hackable code meant results could be shared, reproduced, improved.
🚀 Community Shift
This shifted the research community towards PyTorch.
Static vs Dynamic Graphs
Static graphs require you to compile, wait, and cross fingers the bug reproduces.
Dynamic graphs mean you can drop pdb.set_trace() anywhere and continue iterating.
Nowadays torch.compile gives the best of both worlds: write dynamically, ship something ahead‑of‑time optimised.
Dynamic Graphs Enabled Contribution
- Developers debug at line‑rate — no cold‑start recompiles.
- Pull‑requests remained reproducible overnight, which accelerated trust.
- Static‑graph alternatives stalled and the community consolidated around PyTorch.
Clone the Paper Tonight → Tweak Tomorrow
PyTorch lowered the barrier to implementation — Transformers built on top of that simplicity.
🔍 Live Debugging
2018: BERT fine-tunes meant print(tensor), not recompile & hope.
🤝 Fast Review
Patches were understandable and reproducible — merged quickly, verified quickly.
⚡ Fast Iteration
Experiments shifted from weeks to hours — feedback cycles accelerated.
“One Model · One File” — Why it Matters
# modeling_bert.py — single source of truth
class BertConfig(PretrainedConfig):
...
class BertSelfAttention(nn.Module):
...
class BertLayer(nn.Module):
...
class BertModel(PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.embeddings = BertEmbeddings(config)
self.encoder = nn.ModuleList(
[BertLayer(config) for _ in range(config.num_hidden_layers)]
)
self.init_weights()
- All layers, forward pass, and
from_pretrained()logic live together. - No cross‑file inheritance maze — copy to Colab, hack, and run.
- Reviewers diff one file; merge time dropped from days to hours.
Paradigms Come at a Cost
📈 Community Growth
The scientific and engineering ML community thrived with Transformers.
🔥 PyTorch Synergy
Transformers and PyTorch grew together — adoption fed back into both ecosystems.
🛠️ Maintenance Pressure
We duplicate code on purpose — to preserve clarity, portability, and hackability.
🧬 Pythonic Modularity
The Modularity of python is never far :)
Back to Python: Modular “Mary Shelley” Mode
Compose new blocks via subclass & override.
class GlmMLP(Phi3MLP):
pass
class GlmAttention(LlamaAttention):
def __init__(self, config, layer_idx=None):
super().__init__(config, layer_idx)
self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim,
config.hidden_size, bias=False)
class GlmForCausalLM(LlamaForCausalLM):
pass
AST expands → full modeling file, still hackable.
Back to Python: It's alive!
All the code becomes runnable and a self-contained model definition
class GlmMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.gate_up_proj = nn.Linear(config.hidden_size, 2 * config.intermediate_size, bias=False)
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
self.activation_fn = ACT2FN[config.hidden_act]
def forward(self, hidden_states: torch.FloatTensor) -> torch.FloatTensor:
up_states = self.gate_up_proj(hidden_states)
gate, up_states = up_states.chunk(2, dim=-1)
up_states = up_states * self.activation_fn(gate)
return self.down_proj(up_states)
class GlmAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: GlmConfig, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
self.scaling = self.head_dim**-0.5
self.attention_dropout = config.attention_dropout
self.is_causal = True
self.q_proj = nn.Linear(
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
)
self.k_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.v_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim, config.hidden_size, bias=False)
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_value: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
logger.warning_once(
"`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
else:
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
@use_kernel_forward_from_hub("RMSNorm")
class GlmRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
GlmRMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
def extra_repr(self):
return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
class GlmRotaryEmbedding(nn.Module):
def __init__(self, config: GlmConfig, device=None):
super().__init__()
# BC: "rope_type" was originally "type"
if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
else:
self.rope_type = "default"
self.max_seq_len_cached = config.max_position_embeddings
self.original_max_seq_len = config.max_position_embeddings
self.config = config
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
self.register_buffer("inv_freq", inv_freq, persistent=False)
self.original_inv_freq = self.inv_freq
We keep hackability while reconnecting with Python working paradigms.
Logit Debugger: Trust but Verify
- Hook every
nn.Module; dump logits layer‑by‑layer - Spot ε‑level drifts (LayerNorm, FP16 underflow…)
- JSON traces diffable in CI

DTensor & Tensor‑Parallel API
Before, changing to Tensor Parallel meant changing the code.
from transformers.modeling_utils import PreTrainedModel
from megatron.model import ColumnParallelLinear, RowParallelLinear
class MyTPModel(PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.q_proj = ColumnParallelLinear(config.hidden_size, config.hidden_size)
self.k_proj = ColumnParallelLinear(config.hidden_size, config.hidden_size)
self.v_proj = ColumnParallelLinear(config.hidden_size, config.hidden_size)
self.o_proj = RowParallelLinear(config.hidden_size, config.hidden_size)
Zero‑Config Tensor Parallelism
The tp_plan JSON keeps model code pristine and declarative.
{
"layer.*.self_attn.q_proj": "colwise",
"layer.*.self_attn.k_proj": "colwise",
"layer.*.self_attn.v_proj": "colwise",
"layer.*.self_attn.o_proj": "rowwise"
}Translated to
def translate_to_torch_parallel_style(style: str):
if style == "colwise":
return ColwiseParallel()
elif style == "rowwise":
return RowwiseParallel()
# …
One JSON → 100 B param model on 8 GPUs. Change the plan, not the code.
Improvements, Load faster & stronger: Cache Allocator
0‑copy weight sharding, single cuda Malloc
Faster model loads, even for a 50-shards 100B model (when we were sprinting Llama4!)

Why Python Wins
- Low entry barrier (although hard to master)
- High‑level semantics express low‑level intent
- Seamless C++/Rust extension points
Where Python can bite 🐍
- Interpreter overhead on microkernels (token‑by‑token decode)
- GIL can throttle async host‑side work
- Easy to under‑optimise code fresh out of the lab
All of these can be mitigated: Triton, compiled custom ops, compile‑time fallback, custom kernels
Kernel Hub: Optimised Ops from the Community
Kernel Hub lets any Python program download and hot‑load compiled CUDA/C++ kernels directly from the Hugging Face Hub at runtime.
- Portable – kernels work from arbitrary paths outside
PYTHONPATH. - Unique – load multiple versions of the same op side‑by‑side in one process.
- Compatible – every kernel targets all recent PyTorch wheels (CUDA, ROCm, CPU) and C‑library ABIs.
import torch
from kernels import get_kernel
# Download optimised kernels from the Hugging Face Hub
activation = get_kernel("kernels-community/activation")
x = torch.randn(10, 10, dtype=torch.float16, device="cuda")
y = torch.empty_like(x)
activation.gelu_fast(y, x)
print(y)
Same Transformer code — now with a 3× faster GELU on A100s.
API Design Lessons
🔍 Make Easy Things Obvious
Models load in one line — no boilerplate.
model = AutoModel.from_pretrained("bert-base-uncased")📄 Paper-to-Repo Diff ≈ 0
Code reflects architecture directly.
class LlamaAttention(nn.Module): ...🚀 Prototyping → Production
Same model runs in vLLM for deployment:
LLM(model="llama", model_impl="transformers")🎛️ Hide Sharding, Show Intent
Declarative TP via config:
"q_proj": "colwise"We tune radios without building RF amps. ML should feel the same.
…while empowering those who do build the amps.
Rise of Multimodality
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-8B")
model = AutoModelForConditionalGeneration.from_pretrained("Qwen/Qwen3-8B")
Same API across text · vision · audio
More and more models, with specific processing - need to uniformize
Rise of Multimodality: torch-powered processing
Torch and torchvision ops have replaced np + PIL defaults in transformers
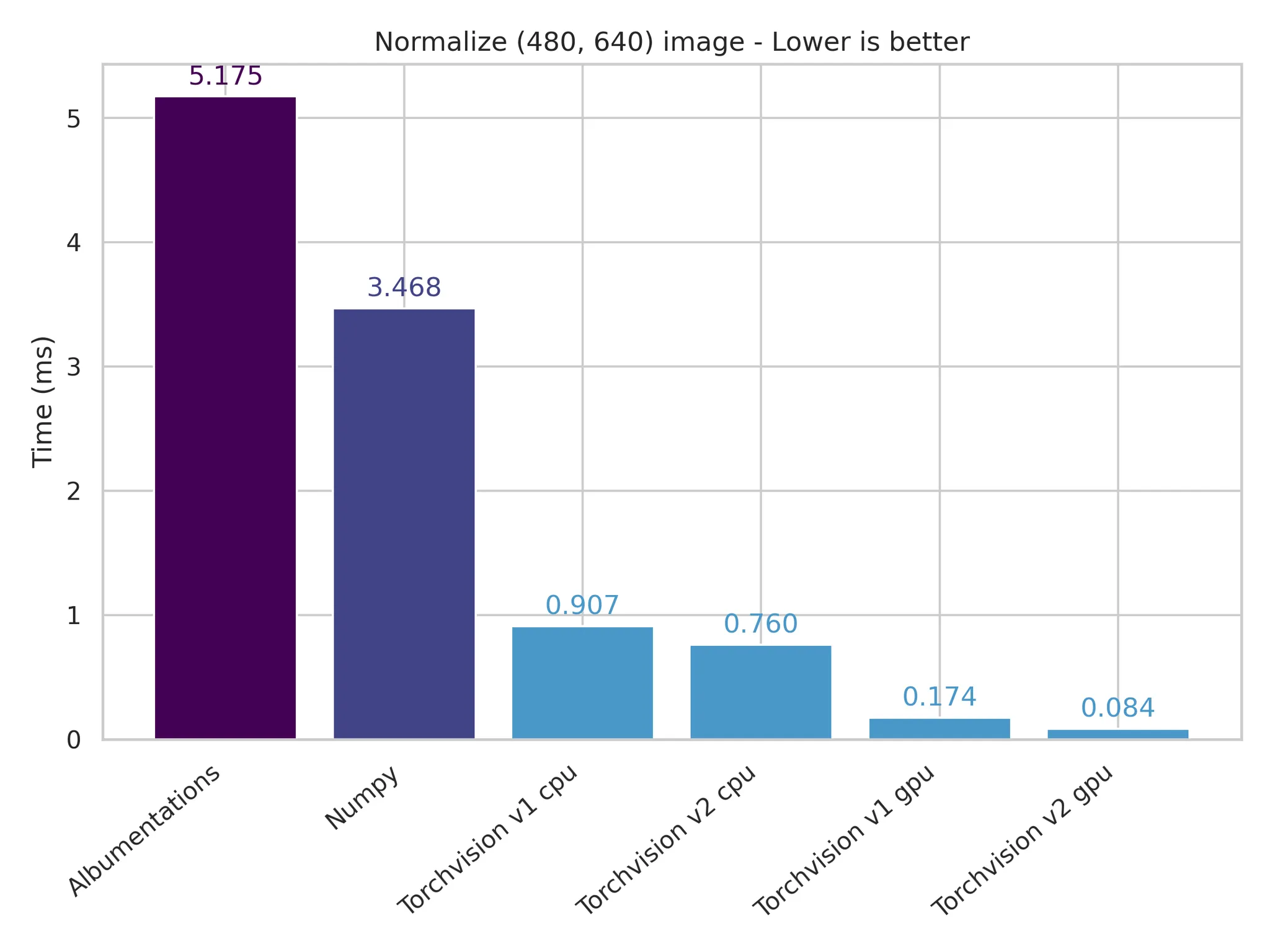
Model Growth by Modality
Beyond Transformers: Ecosystem Reuse
Transformers makes modeling easy. vLLM makes inference fast.
🔧 Prototype with Transformers:
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3.2-1B")
print(pipe("The future of AI is")[0]["generated_text"])
Deploy with vLLM — No Rewrite Needed
vLLM supports transformers models out of the box.
Just specify model_impl="transformers" if needed:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-3.2-1B", model_impl="transformers")
params = SamplingParams(max_tokens=20)
outputs = llm.generate("The future of AI is", sampling_params=params)
print(outputs[0].outputs[0].text)
We also support SGLang now, along with thousands of other libraries!
Transformers × PyTorch — Enabling the Community

Takeaways & The Future
🤝 Symbiotic Growth
PyTorch & transformers grow together
![]()
🧠 Pythonicity × Pragmatism
High-level code, low-level control — a winning combination for fast iteration.
🚢 Models Ship Faster
Open-source models are scaling up — and landing in users' hands faster than ever.
📚 Source of Truth for Model Definitions
We aim to be the canonical reference — while enabling the community to build, remix, and deploy at scale.